Learning-related skills
0096. 최적화(optimization): 신경망 학습의 목적은 손실 함수의 값을 가능한 낮추는 매개변수를 찾는 것(매개변수의 최적값을 찾는 문제), 이러한 문제를 푸는 것.
- 광대하고 복잡한 지형을 지도없이, 눈을 가린 채로 ‘깊은 곳’을 찾아야 함. 이 어려운 상황에서 중요한 단서가 되는 것이 땅의 ‘기울기’.
0097. 확률적 경사 하강법(SGD)

- W는 갱신할 가중치 매개변수, aL/aW는 W에 대한 손실 함수의 기울기, n는 학습률, 화살표는 우변의 값으로 좌변의 값을 갱신한다는 뜻.
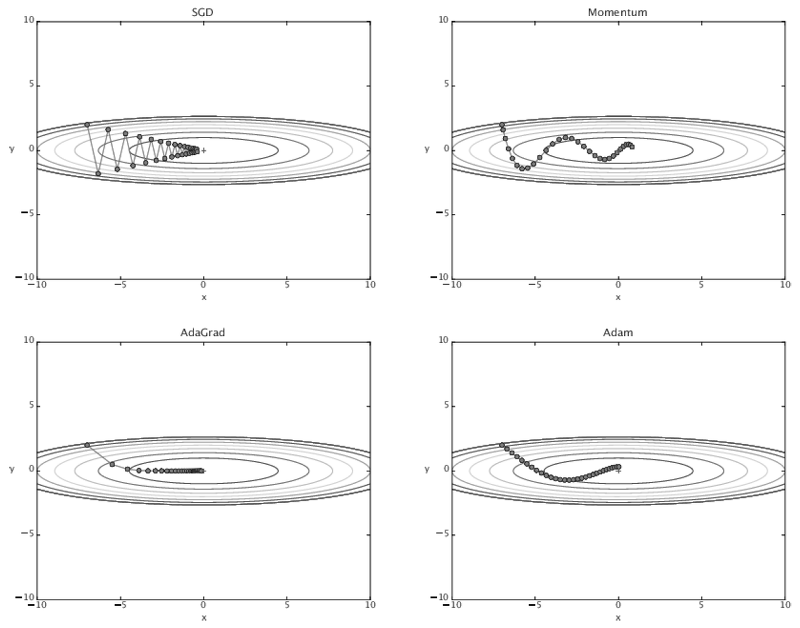
- SGD는 기울어진 방향으로 일정 거리만 가겠다는 단순한 방법.
1
2
3
4
5
6
7
8
9
10
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
optimizer = SGD()
optimizer.update(params, grads)
- 단점: 비등방성(anisotropy: 방향에 따라 성질, 즉 여기서는 기울기가 달라지는 함수)에서는 탐색 경로가 비효율적(지그재그로 탐색). 기울어진 방향이 본래의 최솟값과 다른 방향을 가리켜서.
0098. 모멘텀(Momentum): ‘운동량’을 뜻하는 단어로, 물리와 관계가 있음.

- W는 갱신할 가중치 매개변수, aL/aW은 W에 대한 손실 함수의 기울기, n은 학습률, v는 속도(velocity)
- 기울기 방향으로 힘을 받아 물체가 가속된다는 물리 법칙
- av항은 물체가 아무런 힘을 받지 않을 때 서서히 하강시키는 역할을 함.(a는 0.9등의 값으로 설정) 물리에서의 지면 마찰이나 공기 저항에 해당.
- SGD와 비교하면 ‘지그재그’정도가 덜함.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None # 인스턴스 변수 v가 물체의 속도. v는 초기화 때는 아무 값도 담지 않고, 대신 update()가 처음 호출될 때 매개변수와 같은 구조의 데이터를 딕셔너리 벼수로 저장.
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
0099. 학습률이 너무 작으면 학습시간이 너무 길어지고, 반대로 너무 크면 발산하여 학습이 제대로 이뤄지지 않음. 이 학습률을 정하는 효과적인 기술로 학습률 감소가 있음. 학습을 진행하면서 학습률을 점차 줄어가는 방법. 처음에는 크게 학습하다가 조금씩 작게 학습. 학습률을 서서히 낮추는 가장 간단한 방법은 매개변수 ‘전체’의 학습률 값을 일괄적으로 낮추는 것.
0100. AdaGrad: 개별 매개변수에 적응적으로(adaptive) 학습률을 조정하면서 학습을 진행.

- W는 갱신할 가중치 매개변수, aL/aW는 W에 대한 손실 함수의 기울기, n은 학습률, h는 기존 기울기 값을 제곱(행렬의 원소별 곱셈)하여 계속 더해줌.
- 매개변수를 갱신할 때 1/(h)^(1/2)을 곱해 학습률을 조정. -> 매개변수의 원소 중에서 많이 움직인(크게 갱신된) 원소는 학습률이 낮아짐, 학습률 감소가 매개변수의 원소마다 다르게 적용됨.
- AdaGrad는 과거의 기울기를 제곱하여 계속 더해감. 학습을 진행할수록 갱신 강도가 약해짐. 실제로 무한히 계속 학습하면 어느 순간 갱신량이 0이 되어 전혀 갱신되지 않음. 이 문제를 개선한 기법이 RMSProp. RMSProp은 과거의 모든 기울기를 균일하게 더해가는 것이 아니라, 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영. 이를 지수이동평균(Exponential Moving Average, EMA)이라 하여, 과거 기울기의 반영 규모를 기하급수적으로 감소시킴.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) # 1e-7로 self.h[key]에 0이 담겨 있다 해도 0으로 나누는 사태를 막아줌.
class RMSprop:
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
0101. Adam: 모멘텀은 공이 그릇 바닥을 구르는 듯한 움직임을 보였고, AdaGrad는 매개변수의 원소마다 적응적으로 갱신 정도를 조정함. 이 두 기법을 융합함. 하이퍼파라미터의 ‘편향 보정’이 진행됨.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
0102. SGD, 모멘텀, AdaGrad, Adam 중 모든 문제에 항상 뛰어난 기법이라는 것은 없음. 각자의 장단이 있어 잘 푸는 문제와 서툰 문제가 있음.
0103. 신경망 학습에서 특히 중요한 것이 가중치의 초깃값임. 가중치의 초깃값을 무엇으로 설정하느냐가 신경망 학습의 성패를 가르는 일이 실제로 자주 있음.
0104. 가중치 초깃값을 0으로(정확히는 가중치를 균일한 값으로 설정) 하면 학습이 올바로 이뤄지지 않음. 오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문. 예츨 들어 2층 신경망에서 첫 번째와 두 번째 층의 가중치가 0이라고 가정. 순전파 때 입력층의 가중치가 0이기 때문에 두 번째 층의 뉴런에 모두 같은 값이 전달 됨. 두 번째 층의 모든 뉴런에 같은 값이 입력된다는 것은 역전파 때 두 번째 층의 가중치가 모두 똑같이 갱신된다는 말. 그래서 가중치들은 같은 초깃값에서 시작하고 갱신을 거쳐도 여전히 같은 값을 유지. 가중치를 여러 개 갖는 의미를 사라지게 함. 가중치가 고르게 되어버리는 상황, 가중치의 대칭적인 구조를 막으려면 초깃값을 무작위로 설정해야 함.
0105. 기울기 소실(gradient vanishing): 데이터가 0과 1에 치우쳐 분포하게 되면 역전파의 기울기 값이 점점 작아지다가 사라짐. 층을 깊게하는 딥러닝에서는 더 심각한 문제가 됨.
0106. 각 층의 활성화값은 적당히 고루 분포되어야 함. 층과 층 사이에 적당하게 다양한 데이터가 흐르게 해야 신경망 학습이 효율적으로 이루어짐. 반대로 치우친 데이터가 흐르면 기울기 소실이나 표현력 제한 문제에 빠져 학습이 잘 이루어지지 않음.
0107. Xavier 초깃값: 앞 계층의 노드가 n개라면 표준편차가 1/(n^(1/2))인 분포를 사용. 활성화 함수로 sigmoid나 tanh 등 S자 모양 곡선일 때 사용.
0108. He 초깃값: 앞 계층의 노드가 n개일 때, 펴준편차가 1/(2n^(1/2))인 정규분포를 사용. 활성화 함수로 ReLU를 사용할 때 사용. ReLU는 음의 영역이 0이라서 더 넓게 분포시키기 위해 2배의 계수 필요.
0109. 배치 정규화(Batch Normalization): 각 층에서의 활성화값이 적당히 분포되도록 조정. 데이터 분포를 정규화하는 ‘배치 정규화 계층’을 신경망에 삽입.

- 장점
- 학습을 빨리 진행할 수 있음(학습 속도 개선).
- 학습을 빨리 진행할 수 있음(학습 속도 개선).
- 초깃값에 크게 의존하지 않음(초깃값 선택 장애 안녕!).
- 초깃값에 크게 의존하지 않음(초깃값 선택 장애 안녕!).
- 오버피팅 억제(드롭아웃 등의 필요성 감소).
- 오버피팅 억제(드롭아웃 등의 필요성 감소).
- 배치 정규화는 학습 시 미니배치를 단위로 정규화함. 구체적으로는 데이터 분포가 평균이 0, 분산이 1이 되도록 정규화.

- 여기에는 미니배치 B = {x1, x2, … xm}이라는 m개의 입력 데이터의 집합에 대해 평균과 분산을 구함. 그리고 입력 데이터의 평균과 분산을 구해서 평균이 0, 분산이 1이 되게(적절한 분포가 되게) 정규화함. 입실론 값은 작은 값(예를 들어 10e-7)으로, 0으로 나누는 사태를 예방하는 역할.

- 또, 배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대(scale)와 이동(shift) 변환을 수행. 이 식에서 γ(감마)는 확대를, β(베타)가 이동을 담당. 두 값은 처음에는 1, 0부터 시작하고, 학습하면서 적합한 값으로 조정해 감.

- 이상이 배치 정규화의 알고리즘. 이 알고리즘이 신경망에서 순전파 때 적용됨.
0110. 오버피팅: 신경망이 훈련 데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응하지 못하는 상태. 기계학습은 법용 성능을 지향.
- 오버피팅 발생 원인
- 매개변수가 많고 표현력이 높은 모델.
- 훈련 데이터가 적음.
- 매개변수가 많고 표현력이 높은 모델.
0111. 가중치 감소: 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 페널치를 부과하여 오버피팅을 억제하는 방법. 원래 오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우 많음.
- 신경망 학습의 목적은 손실 함수의 값을 줄이는 것임. 이때, 예를 들어 가중치의 제곱 노름norm (L2 노름)을 손실 함수에 더해줌. 그러면 가중치가 커지는 것을 억제할 수 있음.
- 가중치를 W라 하면 L2 노름에 따른 가중치 감소는 1/2λ(W^2)이 되고, 이를 손실 함수에 더함.
- 여기서 λ람다는 정규화의 세기를 조절하는 하이퍼파라미터. λ를 크게 설정할수록 큰 가중치에 대한 페널티가 커짐.
- 1/2λ(W^2)의 앞쪽 1/2는 1/2λ(W^2)의 미분결과인 λW를 조정하는 역할의 상수.
- L2 노름은 각 원소의 제곱들을 더한 것.
- 간단하게 구현할 수 있고, 어느 정도 지나친 학습을 억제할 수 있으나 신경망 모델이 복잡해지면 가중치 감소만으로 오버피팅을 대응하기 어려워짐.
0112. 드롭아웃: 뉴런을 임의로 삭제하면서 학습하는 방법. 훈련 때 은닉층의 뉴런을 무작위로 골라 삭제. 시험 때는 모든 뉴런에 신호 전달, 단 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flag=True):
if train_flag:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio # self.mask는 x와 형상이 같은 배열을 무작위로 생성하고, 그 값이 dropout_ratio보다 큰 원소만 True로 설정.
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout): # 역전파 때의 동작은 ReLU와 같음.
return dout * self.mask # 순전파때 신호를 통과시키는 뉴런은 역전파 때도 신호를 통과시키고, 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호를 차단.
0113. 앙상블 학습: 개별적으로 학습시킨 여러 모델의 출력을 평균 내어 추론. 앙상블 학습은 드롭아웃과 밀접. 드롭아웃이 학습 때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해설할 수 있기 때문. 드롭아웃은 앙상블 학습과 같은 효과를 하나의 네트워크로 구현.
0114. 하이퍼파라미터: 각 층의 뉴런 수, 배치 크기, 매개변수 갱신 시의 학습률과 가중치 감소 등.
- 하이퍼파라미터의 성능을 평가할 때는 시험 데이터를 사용해서 안 됨.
- 시험 데이터를 사용하에 하이퍼파라미터를 조정하면 하이퍼파라미터 값이 시험 데이터에 오버피팅됨.
- 하이퍼파라미터를 조정할 때는 하이퍼파라미터 전용 확인 데이터가 필요함. 이를 validation data라고 부름.
- 훈련 데이터: 매개변수 학습
- 검증 데이터: 하이퍼파라미터 성능 평가
- 시험 데이터: 신경망의 범용 성능 평가
- 훈련 데이터: 매개변수 학습
0115. 하이퍼파라미터를 최적화할 때의 핵심은 하이퍼파라미터의 ‘최적 값’이 존재하는 범위를 조금씩 줄여간다는 것.
- 범위를 조금씩 줄이려면 우선 대략적인 범위를 설정하고 그 범위에서 무작위로 하이퍼파라미터 값을 골라낸(샘플링) 후, 그 값으로 정확도를 평가.
- 정확도를 잘 살피면서 이 작업을 여러 번 반복하여 하이퍼파라미터의 ‘최적 값’의 범위를 좁혀감.
- 신경망에서 하이퍼파라미터 최적화에서는 그리드 서치 같은 규칙적인 탐색보다 무작위로 샘플링하여 탐색하는 편이 좋음. 최종 정확도에 미치는 영향력이 하이퍼파라미터마다 다르기 때문.
- 하이퍼파라미터를 죄적화 할 때는 딥러닝 학습에는 오랜 시간이 걸린다는 점을 기억해야 함. 따라서 나쁠 듯한 값은 일찍 포기하는 것이 좋음. 학습을 위한 에폭을 작게 하여, 1회평가에 걸리는 시간을 단축하는 것이 효과적.
- 0단계: 하이퍼파라미터의 값의 범위를 설정.
- 1단계: 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출.
- 2단계: 1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가.(단, 에폭을 작게 설정.)
- 3단게: 1단계와 2단계를 특정 횟수(100회 등) 반복하여, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힘.
- 0단계: 하이퍼파라미터의 값의 범위를 설정.