Backpropagation
0084. 수치 미분은 단순하고 구현하기 쉽지만 계산 시간이 오래 걸림-> 가중치 매개변수의 기울기를 효율적으로 계산하는 ‘오차역전파법(backpropagation)’
0085. 연쇄법칙: 합성 함수의 미분에 대한 성질. 합성 함수의 미분은 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있음.


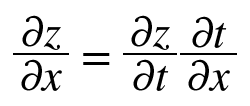
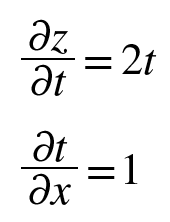
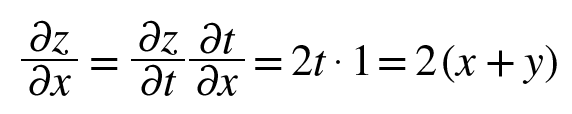
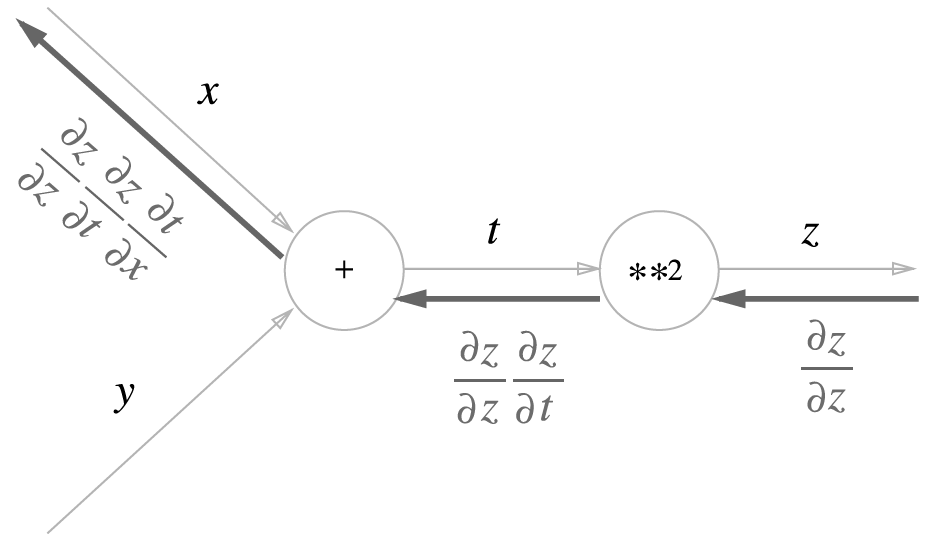
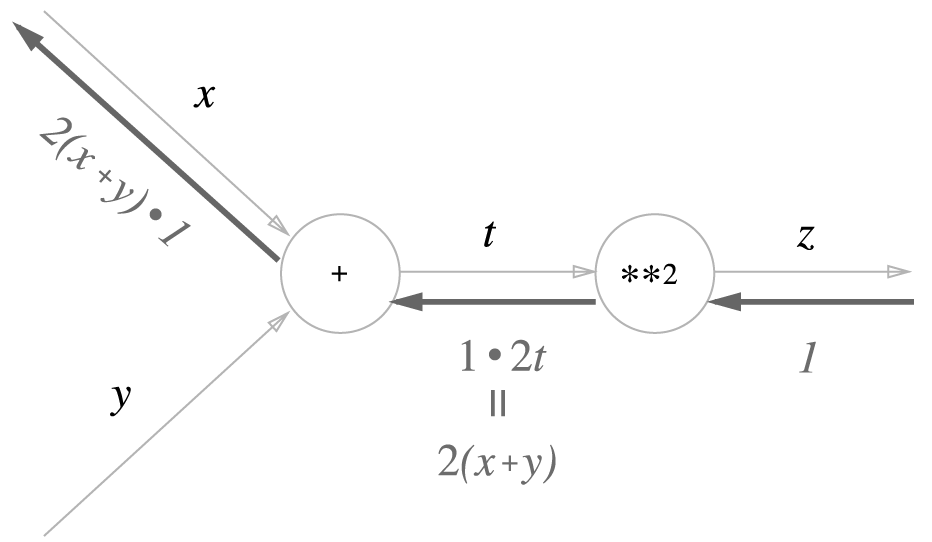
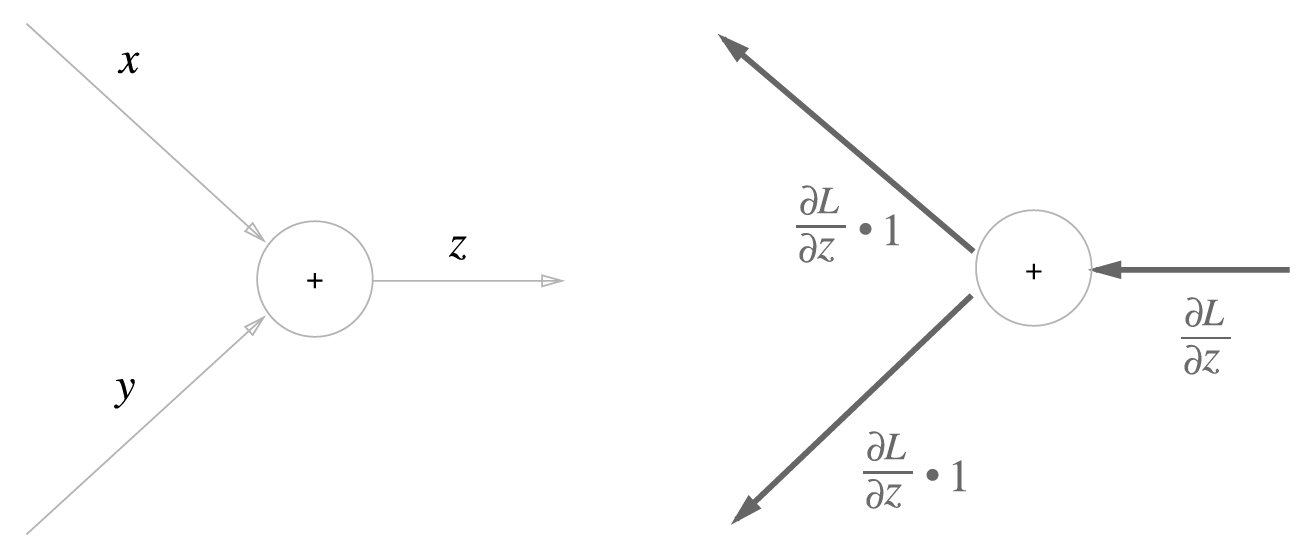
0086. 덧셈 노드의 역전파. 덧셈 노드의 역전파는 입력 값을 그대로 흘려보냄.
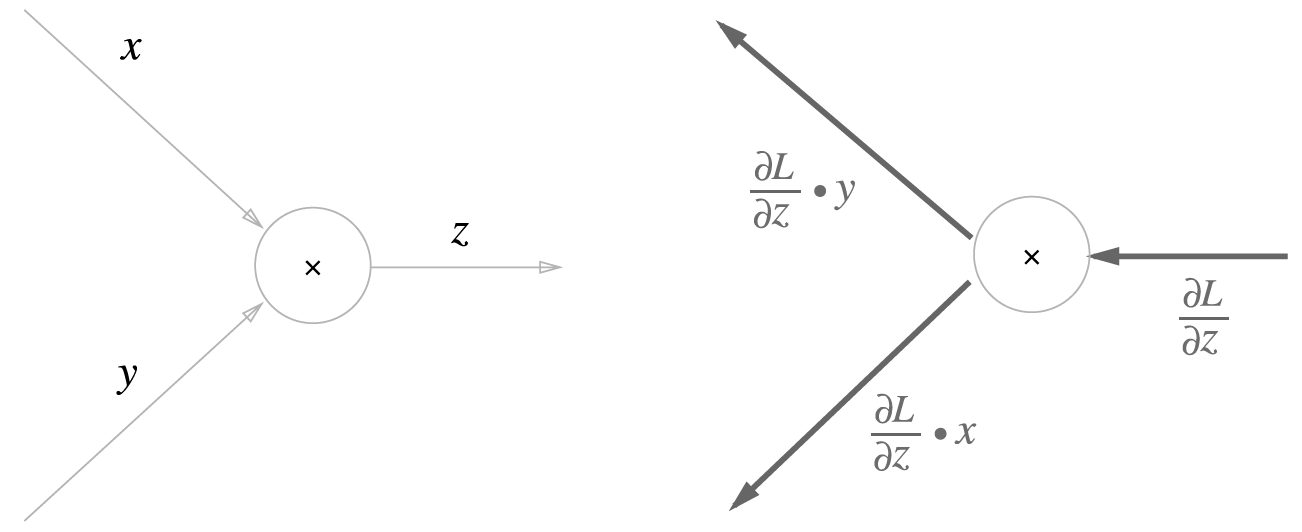
0087. 곰셈 노드의 역전파. 순전파 때의 입력 신호들을 ‘서로 바꾼 값’을 곱하여 하류로 보냄. 그래서 곱셈 노드를 구현할 때는 순전파의 입력 신호를 변수에 저장해둠.
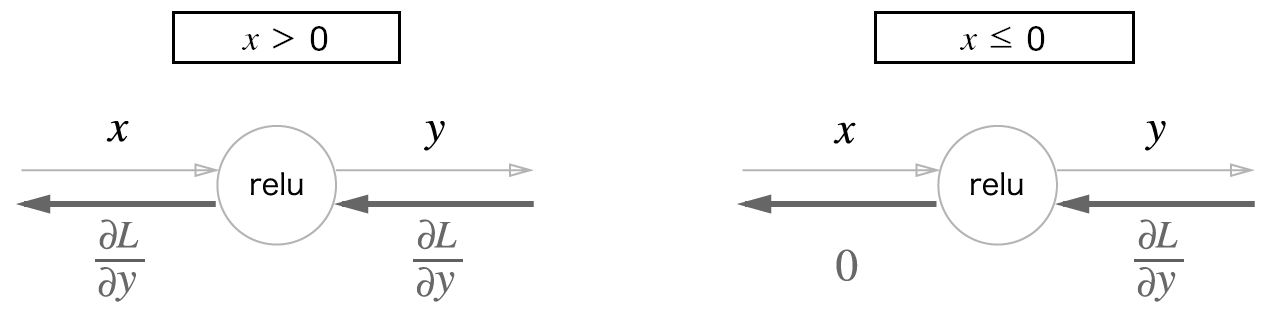
0088. 활성화 함수 ReLU 계층 구현.

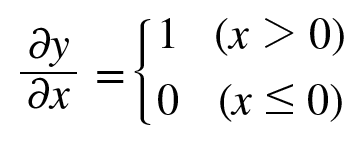
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Relu:
def __init__(self):
self.mask = None # True/Falsle로 구성된 넘파이 배열로, 순전파의 입력인 x의 원소 값이 0이하인 인덱스는 True, 그 외(0보다 큰 원소)는 False로 유지.
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0 # 역전파 때는 순전파 때 만들어둔 mask를 써서 mask의 원소가 True인 곳에는 상류에서 전파된 dout을 0으로 설정.
dx = dout
return dx
0089. 활성화 함수 Sigmoid 계층 구현.
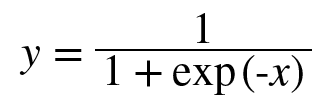


- ’/’노드에서 y = 1/x 를 미분하면, -1/(x^2) = -y^2이 됨.
- ’+’노드는 상류의 값을 여과 없이 하류로 보내는 것이 전부.
- ‘exp’노드는 y = exp(x)연산을 수행.
- ‘x’노드는 순전파 때의 값을 서로 바꿔 곱함.
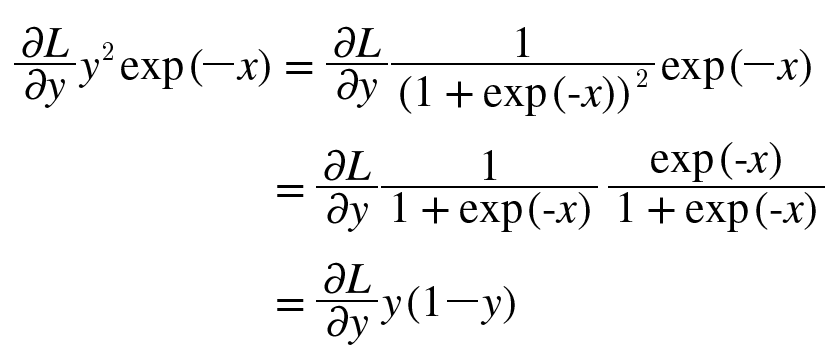
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out # 순전파의 출력을 인스턴스 변수 out에 보관했다가, 역전파 계산 때 그 값을 사용
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
0090. 배치용 Affine(신경망의 순전파 때 수행하는 행렬의 곱) 계층

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx
0091. Softmax-with-Loss 계층(손실 함수인 교차 엔트로피 오차도 포함)


- Softmax 계층은 입력 (a1, a2, a3)를 정규화하여 (y1, y2, y3)를 출력.
- Cross Entropy Error 계층은 Softmax의 출력 (y1, y2, y3)와 정답 레이블 (t1, t2, t3)를 받고, 이 데이터들로부터 손실 L을 출력.
- (y1, y2, y3)는 Softmax 계층의 출력이고 (t1, t2, t3)는 정답 레이블이므로 (y1-t1, y2-t2, y3-t3)는 Softmax 계층의 출력과 정답 레이블의 차분.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 손실
self.y = None # softmax의 출력
self.t = None # 정답 레이블(원핫벡터)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx
0092. 신경망 학습의 전체 그림.
- [전체]
- 신경망에는 적응 가능한 가중치와 편향이 있고, 이 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정을 ‘학습’이라 함.
- [1단계: 미니배치] 훈련 데이터 중 일부를 무작위로 가져옴. 이렇게 선별한 데이터를 미니배치라 하며, 그 미니배치의 손실 함수 값을 줄이는 것이 목표.
- [2단계: 기울기 산출(수치 미분, 오차역전파법)] 미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구함. 기울기는 손실 함수의 값을 가장 작게 하는 방향을 제시.
- [3단계: 매개변수 갱신] 가중치 매개변수를 기울기 방향으로 아주 조금 갱신.
- [4단계: 반복] 1 ~ 3단계 반복
- [1단계: 미니배치] 훈련 데이터 중 일부를 무작위로 가져옴. 이렇게 선별한 데이터를 미니배치라 하며, 그 미니배치의 손실 함수 값을 줄이는 것이 목표.
0093. 오차역전파법을 적용한 신경망 구현.
TwoLayerNet 클래스의 인스턴스 변수
| 인스턴스 변수 | 설명 |
|---|---|
| params | 딕셔너리 변수로, 신경망의 매개변수를 보관. params[‘W1’]은 1번째 층의 가중치, params[‘b1’]은 1번째 층의 편향 |
| layers | 순서가 있는 딕셔너리 변수로, 신경망의 계층을 보관. layers[‘Affine1’], layers[‘Relu1’], layers[‘Affine2’]와 같이 각 계층을 순서대로 유지 |
| lastLayer | 신경망의 마지막 계층. 이 예에서는 SoftmaxWithLoss 계층. |
TwoLayerNet 클래스의 메서드
|메서드|설명| |——|—-| |init(self, input_size, hidden_size, output_size, weight_init_std| 초기화를 수행.
인수는 앞에서부터 입력층 뉴런 수, 은닉층 뉴런 수, 출력층 뉴런 수, 가중치 초기화 시 정규분포의 스케일| |predict(self, x)|예측(추론)을 수행.
인수 x는 이미지 데이터| |loss(self, x, t)|손실 함수의 값을 구함.
인수 x는 이미지 데이터, t는 정답 레이블| |accuracy(self, x, t)|정확도를 구함.| |numerical_gradient(self, x, t)|가중치 매개변수의 기울기를 수치 미분 방식으로 구함.| |gradient(self, x, t)|가중치 매개변수의 기울기를 오차연전파법으로 구함.|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.layers import *
from common.gradient import numerical_gradient
from collections import OrderedDict
class TwoLayerNet:
def __init__(self, intput_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layers.forward(x)
return x
# x: 입력 데이터, t: 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t)
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x: 입력 데이터, t: 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = nemerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# 순전파
self.loss(x, t)
# 역전파
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
0094. 오차역전파법을 사용한 학습 구현하기.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnis
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normaliz=True, ont_hot_label=True)
network = TwoLayerNet(intput_size=784, hidden_size=50, output_size=10)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iter_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 오차역전파법으로 기울기 구함.
grad = netword.gradient(x_batch, t_batch)
# 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epock == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)
0095. 기울기 확인
- 수치 미분은 오차역전파법을 정확히 구현했는지 확인하기 위해 필요.
- 수치 미분은 구현하기 쉬움.
- 수치 미분의 구현에는 버그가 숨어있기 어려운 반면, 오차역전파법은 구현하기 복잡해서 종종 실수를 하곤 함.
- 수치 미분의 결과와 오차역전파법의 결과를 비교하여 오차역전파법을 제대로 구현했는지 검증하곤 함.