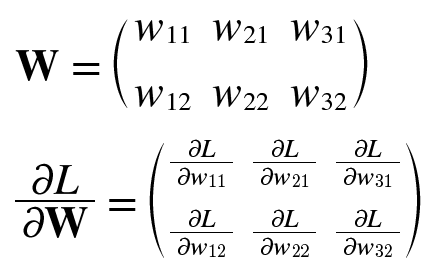Neural network
0050.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 2-3-2-2
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def identity_function(): # 출력층의 활성화 함수. 입력을 그대로 출력하는 항등함수.
return x
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([0.1, 0.4], [0.2, 0.5], [0.3, 0.6])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([0.1, 0.3], [0.2, 0.4])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'] ,network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_fuction(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
0051. 분류: 데이터가 어느 클래스에 속하느냐. (성별분류) -> 소프트맥스 함수
0052. 회귀: 입력 데이터에서 (연속적인) 수치를 예측. (몸무게) -> 항등 함수: 입력을 그대로 출력
0053. 소프트맥스 함수
- 지수함수는 쉽게 아주 큰 값을 내뱉음. 이런 큰 값끼리 나눗셈을 하면 결과 수치가 ‘불안정’해짐. (오버플로)
- 기존의 소프트맥스 함수에 C라는 임의의 정수를 분자와 분모 양 쪽에 곱함.
- C를 지수 함수 exp() 안으로 옮겨 logC로 만들음.
- logC를 C’라는 새로운 기호로 바꿈. C’에 어떤 값을 대입해도 상관 없지만, 오버플로를 막을 목적으로는 입력 신호 중 최댓값을 이용하는 것이 일반적.
- 기존의 소프트맥스 함수에 C라는 임의의 정수를 분자와 분모 양 쪽에 곱함.
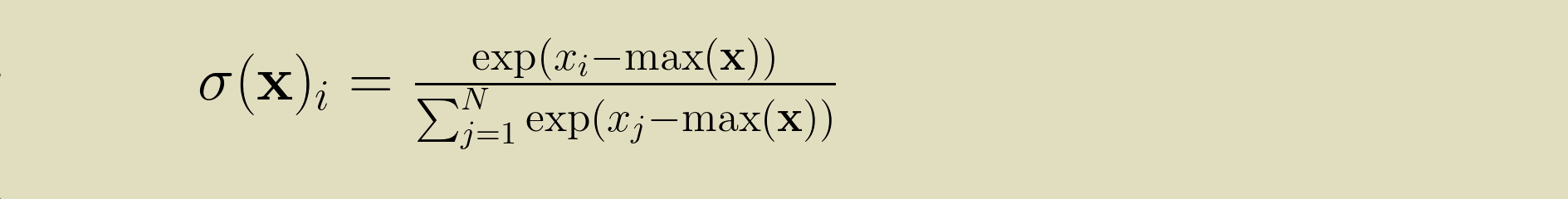
1
2
3
4
5
6
7
8
9
10
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
0054. 소프트맥스 함수의 출력은 0에서 1.0 사이의 실수이고 소프트맥스 함수 출력의 총합은 1 -> 소프트맥스 함수의 출력을 ‘확률’로 해석할 수 있음.
0055. 기계학습의 문제 풀이는 학습과 추론의 두 단계를 거쳐 이루어짐. 학습 단계에서 모델을 학습하고(직업 훈련을 받고), 추론 단계에서 앞서 학습한 모델로 미지의 데이터에 대해서 추론(분류)을 수행함(현장에 나가 진짜 일을 함). 추론 단계에서는 출력층의 소프트맥스 함수를 생략하는 것이 일반적. 신경망을 학습시킬 때는 출력층에서 소프트맥스 함수를 사용.
0056. 정규화: 데이터를 특정 범위로 변환하는 처리
0057. 전처리: 신경망의 입력 데이터에 특정 변환을 가하는 것.
- ex) 입력 이미지 데이터에 대한 전처리 작업으로 정규화 수행.
0058. 배치 처리를 수행함으로써 큰 배열로 이루어진 계싼을 하게 되는데, 컴퓨터에서는 큰 배열을 한꺼번에 계산하는 것이 분활된 작은 배열을 여러 번 검사하는 것보다 빠름.
Neural network learning
0059. 손실함수: 신경망이 학습할 수 있도록 해주는 지표. 이 손실 함수의 결괏값을 가장 작게 만드는 가중치 매개변수를 찾는 것이 학습의 목표.
0060. 특징: 입력 데이터에서 본질적인 데이터(중요한 데이터)를 정확하게 추출할 수 있도록 설계된 변환기
0061. 딥러닝을 종단간 기계학습(end-to-end machine learning)이라고도 함. 데이터(입력)에서 목표한 결과(출력)를 사람의 개입 없이 얻었다는 뜻.
0062. 우리가 원하는 것은 범용적으로 사용할 수 있는 모델이라 훈련 데이터와 시험 데이터로 나눠 학습과 실험을 수행함.
0063. 범용 능력: 아직 보지 못한 데이터(훈련 데이터에 포함되지 않은 데이터)로도 문제를 올바르게 풀어내는 능력.
0064. 오버피팅: 한 데이터셋에만 지나치게 최적화된 상태.
0065. 신경망 학습에서는 현재의 상태를 ‘하나의 지표’로 표현함. 그 지표를 가장 좋게 만들어주는 가중치 매개변수의 값을 탐색함. 신경망 학습에서 사용하는 지표는 손실 함수(loss function)라고 함. 손실 함수는 신경망 성능의 ‘나쁨’을 나타내는 지표. 일반적으로 오차제곱합과 교체 엔트로피 오차를 사용.
0066. 오차제곱합(sum of squares for error, SSE)

- yk는 신경망의 출력(신경망이 추정한 값), tk는 정답 레이블, k는 데이터의 차원 수, 1/2는 미분을 쉽게하기 위해.
- 각 원소의 출력(추정 값)과 정답 레이블(참 값)의 차를 제곱한 후, 그 총합을 구함.
1
2
def sum_squares_error(y, t):
return 0.5 * np.sum((y-t)**2)
0067. 원핫인코딩: 한 원소만 1로 하고 그 외는 0으로 나타내는 표기법.
0068. 교차 엔트로피 오차(cross entropy error, CEE)

- yk는 신경망의 출력, tk는 정답 레이블.
- 실질적으로 정답일 때의 추정(tk가 1일 때의 yk)의 자연로그를 계산.
- 교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정함.
- 자연로그 y=logx의 그래프는 x가 1일 때 y는 0이 되고 x가 0에 가까워질수록 y의 값은 점점 작아짐.
1
2
3
def cross_entropy_error(y, t): # y와 t는 넘파이 배열
delta = 1e-7 # np.log() 함수에 0을 입력하면 마이너스 무한대를 뜻하는 -inf가 되어 더 이상 계산할 수 없음. 아주 작은 값을 더해서 방지
return -np.sum(t * np.log(y + delta))
0069. 훈련 데이터 모두에 대한 손실함수의 합을 구하는 방법. ex) 교차 엔트로피 오차

- N으로 나눔으로써 ‘평균 손실 함수’를 구하는 것.
0070. 미니배치: 훈련 데이터로부터 일부만 골라 학습을 수행.
- 가령 60,000장의 훈련 데이터 중에서 100장을 무작위로 뽑아 그 100장만을 사용하여 학습.
1
2
3
4
5
6
7
def cross_entropy_error(y, t): # (배치용) 교체 엔트로피 오차 구현하기
if y.ndim == 1: # y가 1차원이라면, 즉 데이터 하나당 교차 엔트로피 오차를 구하는 경우 reshape 함수로 데이터의 형상을 바꿔줌.
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
1
2
3
4
5
6
7
def cross_entropy_error(y, t): # 정답 레이블이 원핫인코딩이 아니라 '2', '7' 등의 숫자 레이블로 주어졌을 때
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
0071. 신경망 학습에서는 최적의 매개변수(가중치와 편향)를 탐색할 때 손실 함수의 값을 가능한 한 작게 하는 매개변수 값을 찾음.
0072. 이때 매개변수의 미분(정확히는 기울기)을 계산하고, 그 미분 값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복.
0073. 가중치 매개변수(x)의 손실 함수(f(x))의 미분: 가중치 매개변수의 값을 아주 조금 변화시켰을 때, 손실 함수가 어떻게 변하나
- 만약 이 미분 값이 음수면 그 가중치 매개변수를 양의 방향으로 변화시켜 손실 함수의 값을 줄일 수 있음.
- 반대로, 미분 값이 양수면 가중치 매개변수를 음의 방향으로 변화시켜 손실 함수의 값을 줄일 수 있음.
- 그러나 미분 값이 0이면 가중치 매개변수를 어느 쪽으로 움직여도 손실 함수의 값은 줄어들지 않음. 그래서 가중치 매개변수의 갱신은 거기서 멈춤.
0074. 정확도를 지표로 삼아서는 안 되는 이유: 미분 값이 대부분의 장소에서 이 되어 매개변수를 갱신할 수 없음, 불연속적인 띄엄띄엄한 값으로 바뀜.
0075. 정확도는 매개변수의 미소한 변화에는 거의 반응을 보이지 않고, 반응이 있더라도 그 값이 불연속적으로 갑자기 변화함.
- ‘계단 함수’를 활성화 함수로 사용하지 않는 이유와도 들어맞음.
- 계단 함수는 한순간만 변화를 일으키지만, 시그모이드 함수의 미분(접선)은 출력이 연속적으로 변하고 곡선의 기울이도 연속적으로 변하여 시그모이드 함수의 미분은 어느 장소라도 0이 되지 않음.
0076. 미분: 한 순간의 변화량. 함수의 기울기.
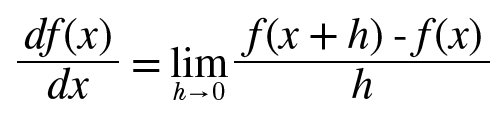
- x의 ‘작은 변화’가 함수 f(x)를 얼마나 변화시키느냐
0077. 수치 미분: 아주 작은 차분으로 미분.
1
2
3
def numerical_diff(f, x):
f = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h) # 중심/중앙 차분
0078. 편미분: 변수가 여럿인 함수에 대한 미분. <- 여러 변수 중 목표 변수 하나에 초점을 맞추고 다른 변수는 값을 고정함.
0079. 기울기: 모든 변수의 편미분을 벡터로 정리한 것.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # x와 형상이 같은 배열을 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val -h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
return grad
0080. 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향
0081. 경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동.
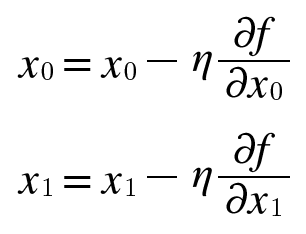
- 에타(n)는 갱신하는 양. 학습률.
1
2
3
4
5
6
7
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
0082. 학습률 같은 매개변수를 하이퍼파라미터라고 함.
0083. 신경망 학습에서 구하는 기울기는 가중치 매개변수에 대한 손실 함수의 기울기